C/López de Hoyos 64, 1G. 28002 Madrid, España
Plataforma Conversacional de Análisis de Datos
Sumiriko
IA Generativa, Arquitectura Multi-Agente, Análisis de Datos & RAG
Diseñamos una solución que transforma la forma en que las organizaciones consultan y explotan su información crítica de negocio. A través de un modelo de Inteligencia Artificial Generativa, hemos desarrollado una plataforma conversacional que permite a cualquier usuario obtener insights complejos mediante lenguaje natural, eliminando barreras técnicas y reduciendo drásticamente los tiempos de respuesta. Nuestro enfoque multi-agente especializado no solo responde preguntas sobre bases de datos SQL, sino que integra capacidades de generación de gráficas, análisis de documentos y procesamiento de archivos (CSV, Excel, PDF). Todo ello desplegado en un entorno On-Premise que garantiza la confidencialidad de los datos, con arquitectura híbrida preparada para escalar a la nube según necesidades puntuales de computación, manteniendo siempre el control total sobre la información sensible.
Retos
- Arquitectura multi-agente especializada: Diseño de un sistema router (Planner) que dirige consultas a asistentes especializados (SQL, Gráficos, Análisis documental), optimizando la precisión de respuestas según el contexto de cada pregunta.
- Generación automática de SQL y visualizaciones: Implementación de agentes capaces de traducir lenguaje natural a consultas SQL válidas contra SQL Server, generando automáticamente gráficos interactivos cuando la pregunta requiere representación visual.
- Integración fluida con Open WebUI para experiencia conversacional: Desarrollo de pipelines personalizados que conectan LangGraph con Open WebUI, implementando procesamiento asíncrono mediante colas Redis para mantener la interfaz responsiva durante operaciones de larga duración. Gestión de streaming de respuestas, estado conversacional y renderizado de gráficos en formato chatbot accesible para usuarios no técnicos.
- Seguridad y control On-Premise con escalabilidad híbrida: Despliegue de modelos LLM locales garantizando confidencialidad, con arquitectura preparada para consumo puntual de recursos Azure sin comprometer la privacidad de datos.
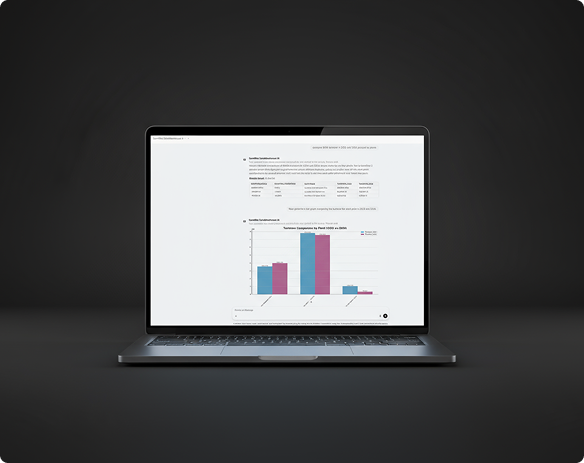
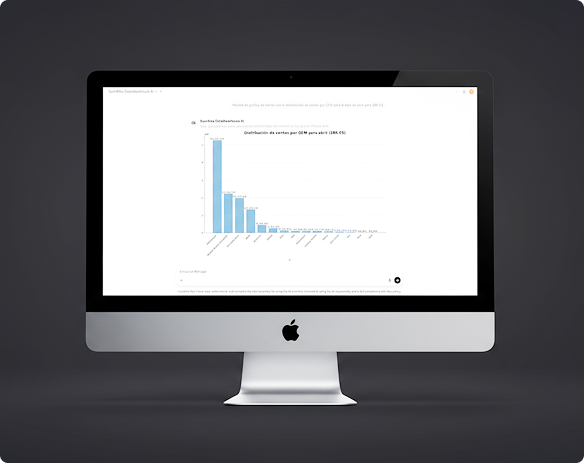
Factores claves de éxito
Orquestación multi-agente con LangGraph
Utilizamos LangGraph para implementar una arquitectura de grafo dirigido con subgrafos reutilizables, permitiendo flujos complejos de decisión y manejo de errores con reintentos automáticos. Esta arquitectura modular facilita la escalabilidad y mantenimiento del sistema.
Selección estratégica de LLMs especializados
Combinamos diferentes modelos según la tarea: utilizamos un modelo para routing y respuestas en lenguaje natural, y otro modelo para generación de código SQL. Esta estrategia optimiza costos computacionales y precisión.
Sistema de contexto inteligente basado en YAML
Implementamos un sistema de metadatos de esquema de base de datos pre-definido en YAML que evita consultas dinámicas costosas. El filtrado inteligente de tablas relevantes reduce el contexto enviado al LLM, mejorando la precisión y reduciendo latencia en un 60%.
Infraestructura asíncrona con Redis y workers
Diseñamos una arquitectura desacoplada usando colas Redis que permite procesamiento asíncrono de consultas complejas, manteniendo la interfaz responsiva (Open WebUI) mientras se ejecutan operaciones de larga duración en workers independientes.
Generación automática de visualizaciones con validación de volumen
El Graph Assistant incluye lógica de decisión (LLM-based) para determinar si reutilizar datos existentes en conversación o ejecutar nuevas consultas SQL, optimizando recursos. Además, valida el volumen de datos antes de renderizar gráficos, previniendo errores de memoria.
Metodología

Prueba de concepto iterativa

Design Thinking aplicado a arquitectura de agentes

Desarrollo modular con subgrafos reutilizables

Testing con datos sintéticos y validación con dominio
Despliegue gradual con monitorización
Prueba de concepto iterativa
Design Thinking aplicado a arquitectura de agentes
Desarrollo modular con subgrafos reutilizables
Testing con datos sintéticos y validación con dominio
Despliegue gradual con monitorización
Resultados

- La solución desarrollada permitió centralizar toda la información crítica de negocio y acceder a ella mediante un asistente conversacional, reduciendo de forma significativa el tiempo necesario para obtener insights relevantes. Gracias al modelo de IA, los usuarios sin conocimientos técnicos pueden consultar bases de datos complejas y recibir análisis completos en segundos, sustituyendo procesos manuales que antes requerían horas. La automatización del procesamiento documental y la generación inmediata de gráficas y resúmenes mejoró la eficiencia operativa y aceleró la toma de decisiones.
- La plataforma, desplegada en un entorno On-Premise seguro y con arquitectura híbrida, garantiza total control sobre los datos sensibles mientras permite escalar la computación cuando es necesario.